Web 2.0 and Literary Criticism

To collect essays into a cluster, such as this one for Contemporaries, creates a casing for those essays to inhabit. Within this casing, the essays's proximity to one another affects the way each is read. It is similar to joining words together to create a full sentence. Proximity puts elements (words, essays) in relation to one another, and by sharing space (and possibly time), connections arise. Concepts might appear more significant if repeated throughout the issue, and meaning is inferred from sequence. Data visualization offers ways of seeing these relationships of proximity.
Zooming in to the word level, imagine if I were to say two words together, without context, and ask you to make a connection. Imagine if I were to say "character" and "sci-fi" or "character" and "tweet." There are numerous ways to connect the pairings. The latter could call to mind the number of characters allowed in a tweet, or the characters of twitter fiction, or even what a tweet might say about a person's character. To eliminate the narratives and focus only on two words eliminates the directional line of reading and the inferred meaning. Doing so is not meant to replace reading or the network of a complete sentence. It is a generative exercise that compliments reading and research. Compare this to the sentence: "There are 280 characters allowed in a tweet." Brainstorming connections between the words "character" and "tweet" and then reading the full sentence, "There are 280 characters allowed in a tweet," could inspire follow up questions: is a person's character revealed in 280 characters, how do writers create characters using only 280 characters, and so on.
This is an abstract exercise that can be turned into a concrete visualization. Let's zoom back out to focus on this cluster's collection of essays. Removing the larger narratives and contexts of the essays to leave only the most frequently occurring words is a way to skim or pre-read. It also serves as a launch pad for further inquiry. It is a way to reshape and visualize the information, the way a painter might turn her canvas upside down to get a new perspective of her work.
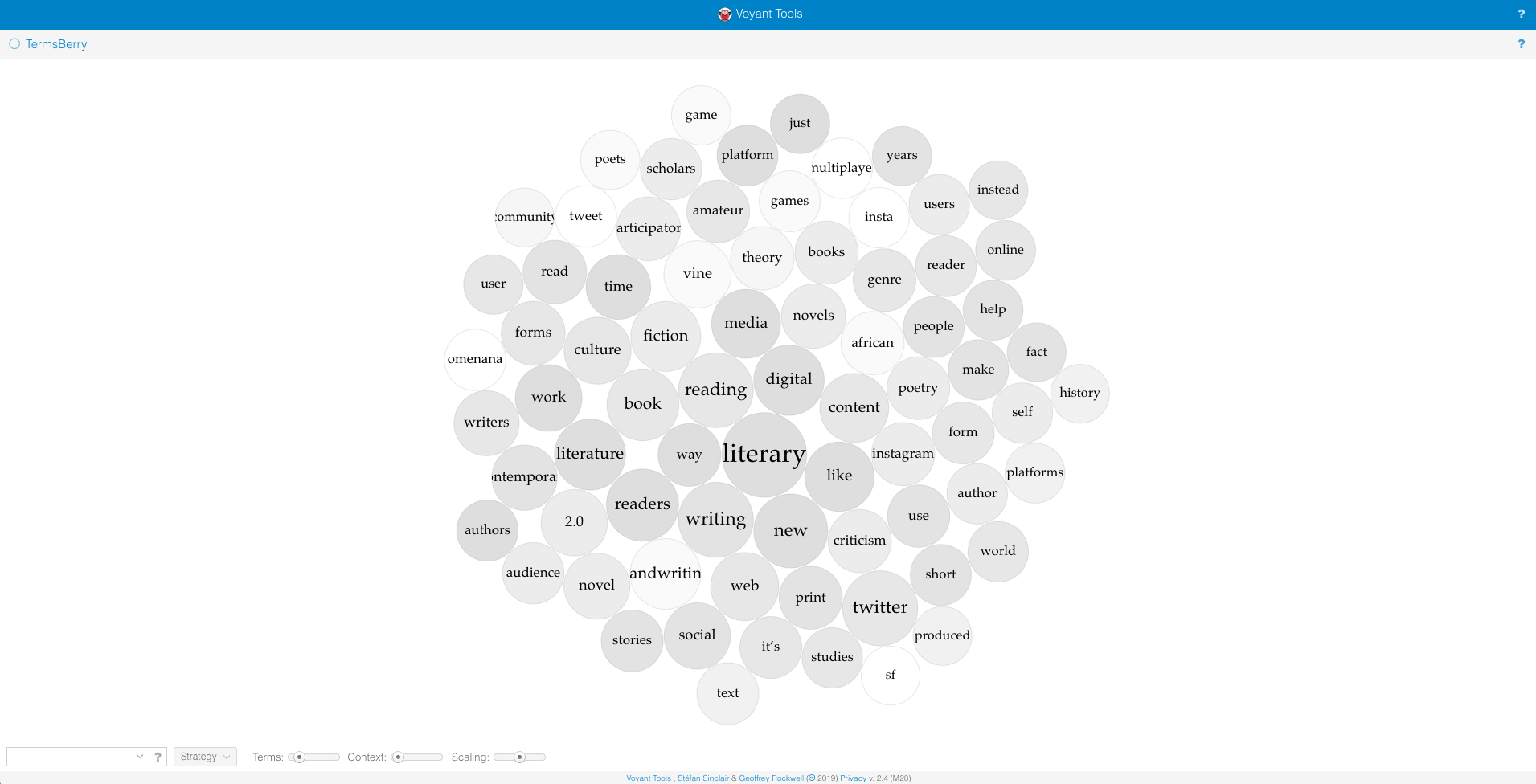
TermsBerry from Voyant allows us to visualize the connections between words in large collections of text, such as this cluster. Using Voyant, the cluster is transformed. Visualizing the top 75 most-used words of the essays, together as one visual entity, distills the focus areas to a collection of single words. We can immediately notice their frequency and the relationships between these words, in this case a relationship that is based on proximity, or nearness, indicating that the words share space, are near to each other, and therefore are building a larger narrative together. Stripping away that larger narrative and only focusing on the words and their proximity to one another is a type of transformation—we are remixing the content of this issue. The interactivity allows for multi-directional reading.
TermsBerry is a free visualization tool provided by Voyant, a platform used to read and analyze a text-based dataset. After uploading a document or a collection of documents, TermsBerry enables a user to create a visualization of the terms that appear most frequently in the document(s) and their proximity to each other—based on how often they appear within two words to the right or left of each other.
I uploaded each of the Word.doc files containing the essays into Voyant to produce the resulting TermsBerry (Screenshot: Figure A, Interactive: Figure D). The image shows the high-frequency terms and their collocates (words appearing in close proximity). In the center of the TermsBerry are the terms that appear most often: for example, "literary," "reading," and "digital." The darker the bubble, the higher the number of articles containing the term. When you hover your curser over a bubble, the selected term becomes the keyword; the other bubbles highlighted indicate the terms that appear in close proximity to the selected keyword. For example, when you hover over "digital," bubbles across the TermBerry become highlighted, showing that digital often appears next to "media," "platforms," and "literary," among others (Figure B).
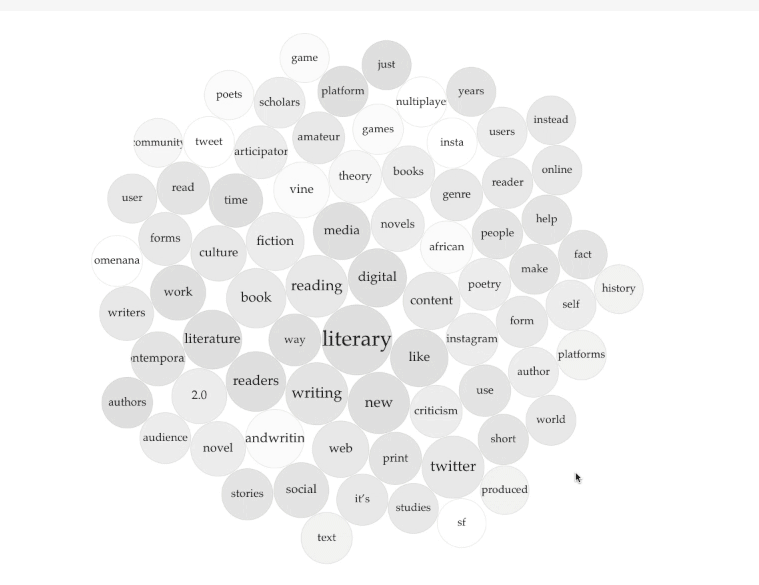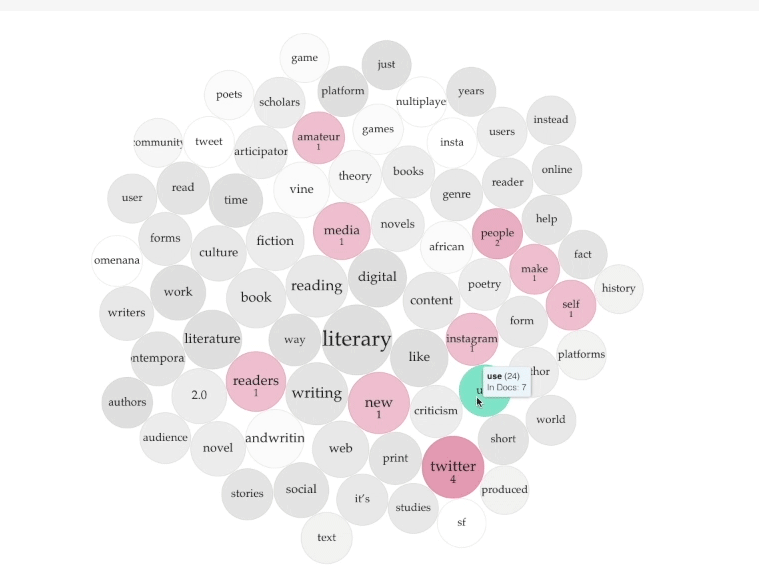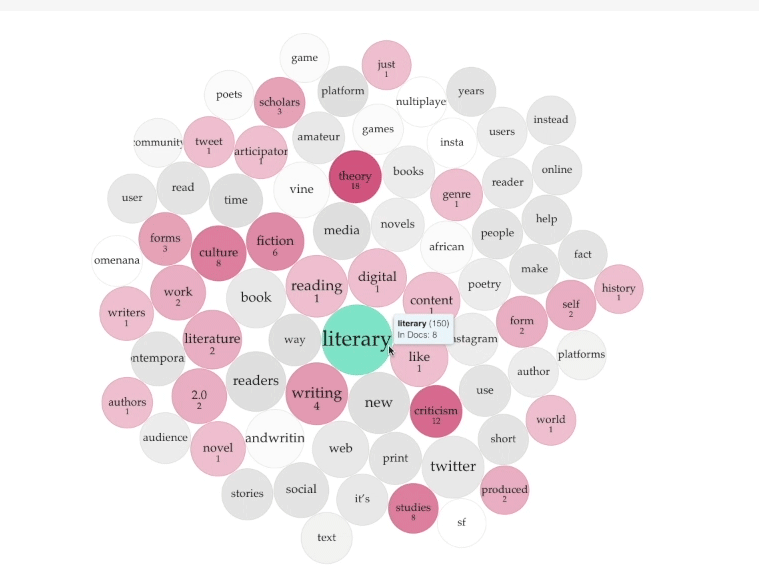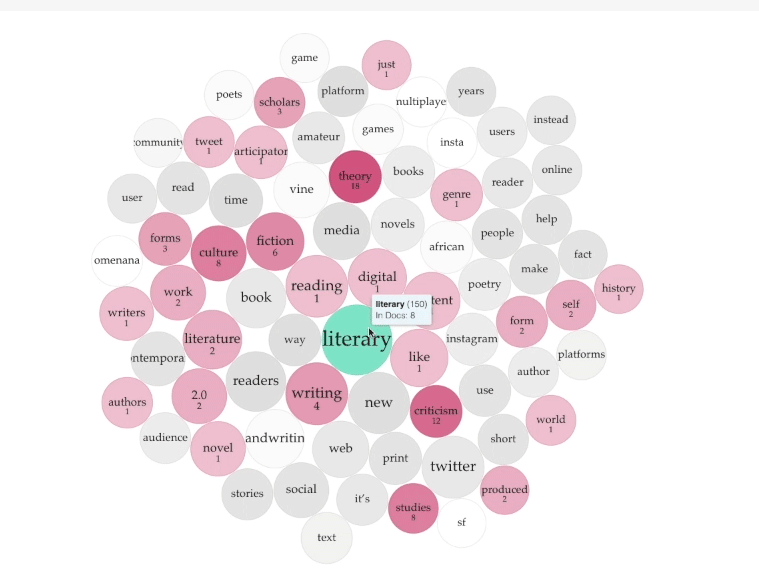
Let's take one example of a finding from the TermBerry visualization as a starting point for interpretation of the cluster: the keywords "Twitter" and "tweet." "Twitter" is mentioned in six of the eight essays, 73 times in total, and "tweet" is mentioned in only one of the essays, 22 times in total. The disproportion in appearance frequency, with "Twitter" being far higher, might suggest that most of the articles focus more on the platform than the content generated by users. What might that mean for thinking about literary criticism 2.0, as represented by this cluster?
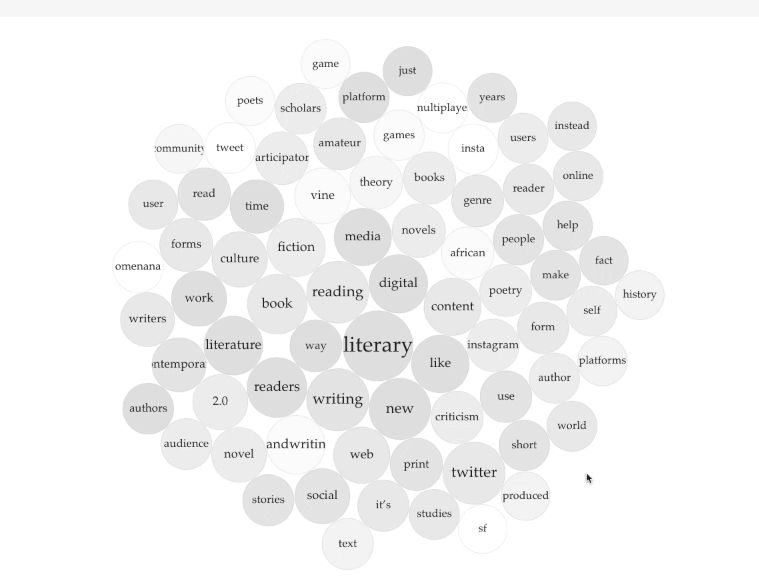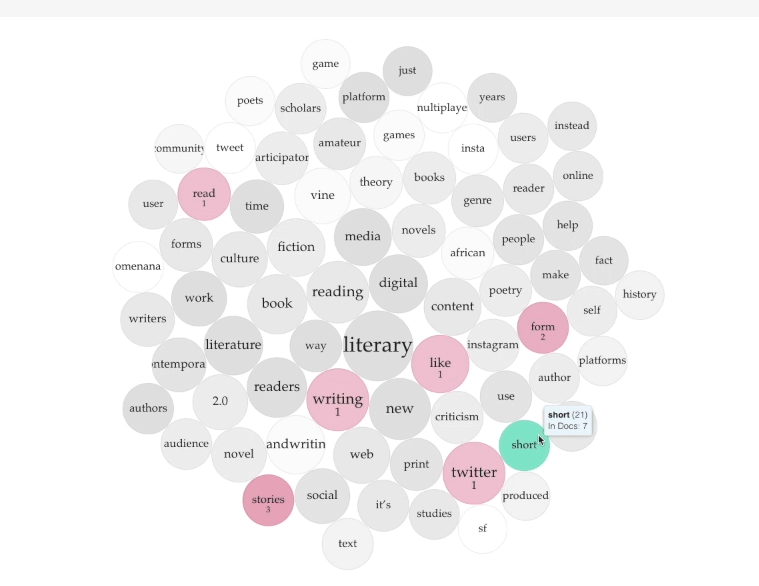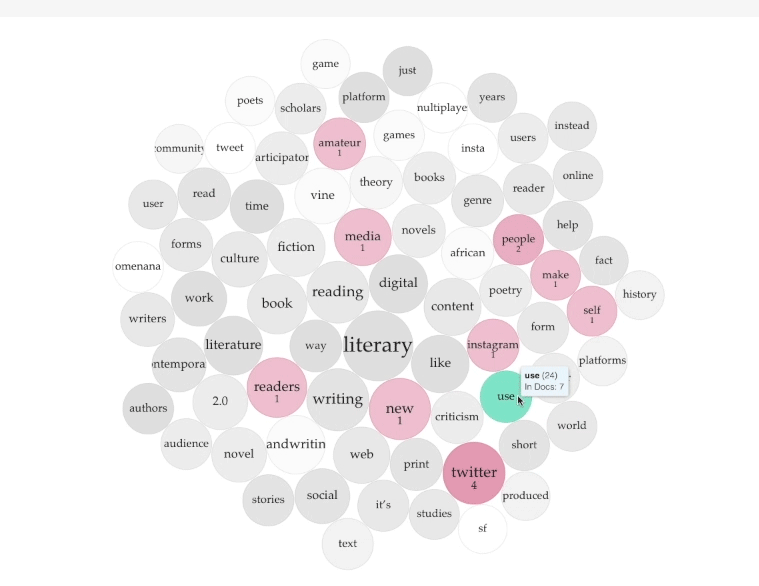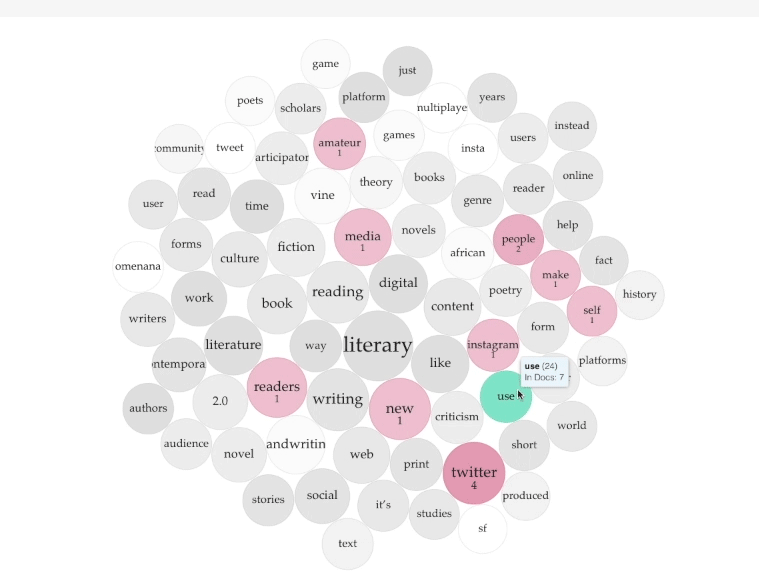
Or hover over the bubble "use." Terms such as "Twitter," "Instagram," and "media" highlight to show they appear in close proximity to "use." Of course, one can "use" each of these platforms. Yet, what is interesting is that terms such as "people," "readers," and "self" also highlight (Figure C). Questions arise such as: how are readers used by the platform, how are we using ourselves when we engage with these platforms, how do readers use media, and how is media using us.
TermsBerry showcases connections between terms and ideas while removing the larger narrative and network of the essays. It operates through the paradigm of proximity, prompting us to consider the relationship between words and why that matters. For a cluster of essays about the networked web, this process makes manifest ideas about clustering. The TermsBerry image creates a small cluster of terms for the user to fill in the blanks or create new connections between associated words; it is a condensed and dynamic method to visualize and transform our ways of seeing.
Figure D
Tina Lumbis has her MFA in Creative Writing from San Diego State University. She teaches literature, creative writing, and digital humanities related workshops in both academic and non-traditional settings, has presented work at the Electronic Literature Organization Conference, and has been published by a variety of online and print journals.
Related reading
 Web 2.0 and Literary Criticism
Multiplayer Lit/Multiplayer Crit
The Participatory Cultures of Omenana: Reading and Writing on a Nigerian SF Website
Do It for the Vine: Literary Reviews and Online Amplification
Can Literary Theory be Participatory?
The Handwritten Styles of Instagram Poetry
Studying and Preserving the Global Networks of Twitter Literature
Close Shaves with Content
Prescribed Print: Bibliotherapy after Web 2.0
Literary Criticism 2.0: Emerging Ideas
Web 2.0 and Literary Criticism
Multiplayer Lit/Multiplayer Crit
The Participatory Cultures of Omenana: Reading and Writing on a Nigerian SF Website
Do It for the Vine: Literary Reviews and Online Amplification
Can Literary Theory be Participatory?
The Handwritten Styles of Instagram Poetry
Studying and Preserving the Global Networks of Twitter Literature
Close Shaves with Content
Prescribed Print: Bibliotherapy after Web 2.0
Literary Criticism 2.0: Emerging Ideas