Reading with Algorithms

"NOT AVAILABLE" was the phrase that appeared repeatedly in the data Amazon's Kindle app had collected on me. It was my responsibility to turn the group's .csv files into graphs, meaning I was privy to all the other participants' data too. This same "NOT AVAILABLE" also cropped up from time to time in their files, although never nearly so frequently as it did in mine. My theory remains that the decrepit old laptop I had been using to read the novel was somehow incompatible with the Kindle app's attempts at data harvesting. I joked that I had somehow outwitted the algorithm, but I was disappointed, if not necessarily surprised. The app regularly had problems syncing to the last place I'd read, it would shut down and restart at random points throughout, and generally felt a bit glitchy. Besides the few times I'd briefly switched to reading on my iPhone, there was no record of the times I started reading, turned each page, closed the book, nor the details of my interactions with the toolbar, my annotations, the colors I used to highlight. Nonetheless, this was information I now had on other participants.
* * *
Our writing collective emerged from Privacy Settings, a reading group that met at the University of Oxford in June of 2022. Our initial aim was to find ways to reflect on the place of reading within a landscape of what Shoshana Zuboff calls "rendition" — or, the "concrete operational practices" of surveillance capitalism in which "human experience is claimed as raw material for datafication and all that follows, from manufacturing to sales."1 To investigate this dimension of digital reading — and the permeating fact of datafication, more broadly — we each read the same novel on the Kindle app, the virtual version of Amazon's famous e-reading device. The text we consumed and discussed was Sally Rooney's 2021 Beautiful World, Where Are You, a prominent contemporary novel in the literary marketplaces of the United States, Canada, the Republic of Ireland, and the United Kingdom, as well as the source of frequent debate, both online and offline. Due to the novel's commercial success and market appeal — to give only one example, it sold more than 40,000 copies in its first five days on sale in the UK — to have read Beautiful World on the Kindle app in 2022 is one way of inhabiting an identifiable "type" of fiction reader in the third decade of the twenty-first century.2
In 2010, only three years after the original Kindle appeared on the market, Ted Striphas set out, with considerable clarity, to describe how the device "runs afoul of the liberal belief in the sanctity of reading and hence the impulse to safeguard the sovereignty of readers." For Striphas, the Kindle uniquely engendered an intensified individual vulnerability to corporate and state control alike.3 Aiming to examine this terrain more closely, we requested our Kindle app data from Amazon after finishing the novel and pooled the results. These data cover individual app usage and its delivery is currently guaranteed by data protection laws in various territories. By bringing digital reading under experimental conditions and then reflecting on the harvested data, we aim to shed light on what — in a legal framework — is now called the "data subject." This term appears in numerous regulatory contexts, including the European Union General Data Protection Regulation (GDPR), the UK Data Protection Act (UKDPA), and the California Consumer Privacy Act (CCPA).
The data subject is, in other words, the amalgamation of the analyzable metrics, statistics, and crude figures that we become when registered and processed by legally permissible regimes of data rendition. Simone Browne's expansion of Frantz Fanon's concept of epidermalization as "what happens when certain bodies are rendered as digitized code," is also relevant here: with it, we can also understand the data subject as a result of algorithms that are "the computational means through which the body, or more specifically parts, pieces, and, increasingly, performances of the body are mathematically coded as data."4 This fragmented selection that takes the performances of certain bodies and turns them into coherent numerical entities is a legal fiction, the result of the encounter between the major protagonists of platform capitalism and liberal juridical regimes playing catch-up with the extraordinary pace of technological change.
Seven participants were involved in our study; we could never hope to replicate a representative microcosm of the colossal database that Amazon keeps. Despite our small sample, the opacity and partiality of the data that Amazon returns to its readers upon request is immediately evident. These harvested metrics are, one, difficult to parse, and, two, returned to data subjects without any glossary or accompanying narrative. Instead, the precise function of an individual's data — the uses Amazon puts that data to — can only be guessed at, hidden behind a screen of commercial sensitivity and prefabricated communications. In a sense, data requested from companies like Amazon offer no hope of repossession or reclamation, nor does it provide any revelatory access to what happens to our information once it is accumulated. All this information can ultimately represent, therefore, is the material traces and foundational matter of the data subject. The data returned by Amazon to its users tell us more about the juridical regimes that currently determine our digital experience than about the companies that mediate that experience. Because the receipt of requested data indicates a bare minimum operation — a legally-mandated concession to users — it also exists, like many rights, within the realm of potentiality. How many users habitually request their data back from the platforms that they use consistently throughout the day, every day? Presenting this information, then, as an analytic object reveals one particular incarnation of a central tension of life under platform capitalism. If certain rights are deemed to be inherent to the data subject, as they have been to many other kinds of legal subject, what would it look like to actualize those rights, to make meaning from them, or to expose their limitations?
Accessing the Data Subject
Originating in Oxford, our group's data requests to Amazon came under the jurisdiction of UK law. Following the UK's departure from the European Union (EU), the UKDPA of 2018 still incorporates the EU's protocols for GDPR to the extent that it uses much of the same text. Both legal frameworks state, for example, that the "data subject" has the right from a data "controller" to "confirmation as to whether or not personal data concerning him or her are being processed"; additionally, "where that is the case, access to the personal data" is a legal right, as well as access to other associated information.5 The "Request My Data" page at amazon.co.uk represents Amazon's concession to these laws. It contains sixteen separate items, ranging from the Kindle data we requested to data on addresses, past orders, music and video settings, and data from the Alexa and Echo devices.
Our data requests came through on average within about a week, though repeat requests yielded slower return times, and some were only fulfilled following engagement with Amazon's customer services interface. Amazon stores data extracted from Kindle app usage in the same place as data taken from the physical Kindle device. Those data are returned to the data subject as a variety of .csv files. One fact that became evident in pooling our Kindle app data is that not all data subjects are equal under Amazon's watch. Nevertheless, though individuals in our group accessed the Kindle app on a range of devices — iPhones, iPads, laptops, Androids, with some sticking to one device and others shuttling between multiple devices — and received various sorts and sizes of data files from Amazon, there was still a high enough signal-to-noise ratio in the data we received to meaningfully process that data.
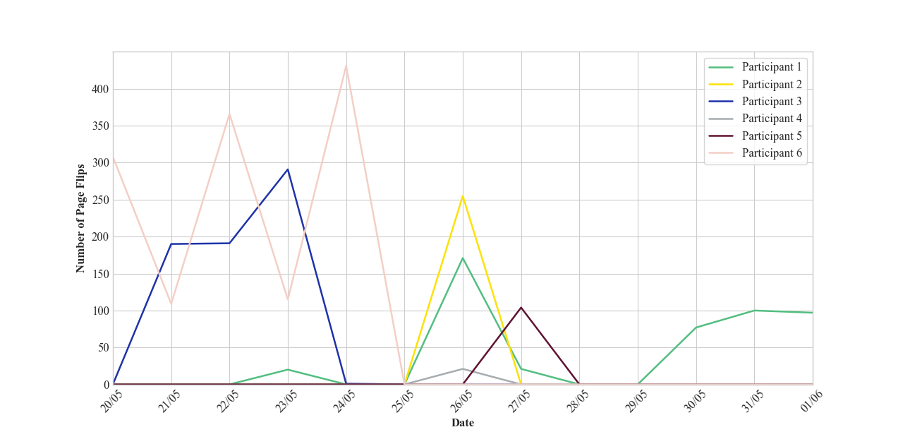
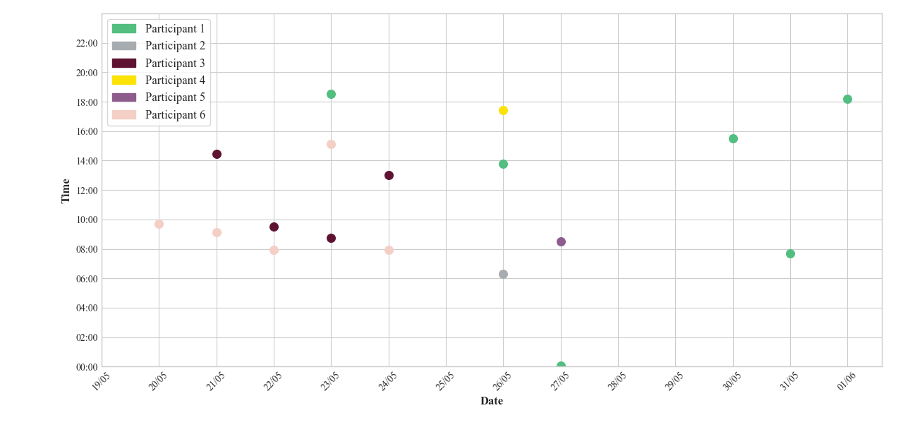
One analytic avenue opened up by our dataset was descriptive. Figures 1 and 2 exemplify the ways that Amazon tracks the reading practices of individual users. Figure 1 charts the page flips of Participants 1-6 across a thirteen-day period (Participant 7's reading sessions fell outside this timeframe). Amazon recorded the number of page turns for each reading session as a data point alongside ten other data points, including timestamps for the beginning and end of each session and milliseconds spent reading. In pooling our data, we were able to create behavioral maps with Amazon's data. Figure 2 shows how, using the collected data, we could compare the times at which each participant began reading across a thirteen-day period. The different scales of these two graphs create a granular picture of reading: reading as reducible to speeds, intensities, and gradients; and reading as a trackable habit or analyzable event. However, the extent to which these behavioral data meaningfully connect with our experiences of reading is negligible, bringing the phantasmic abstraction of the data subject into stark relief.
* * *
Having initially struggled to find which line represented "me" on the graph plotting our Daily Page Flips, light dawned when I noticed the moderate green spike on May 26, followed by an approximate plateau from May 30 through June 1. On my birthday, May 26, I'd taken a train from Oxford to London, during which journey I read Rooney. (The much smaller number of flips the next day is a testament to a hangover). And from May 30 to June 1, I took several train journeys from London to Cambridge. Sure enough, a subsequent graph shows that on these days I read, more or less at 8 am and 6 pm, on either side of my all-day appointments at Girton College.
Amazon, then, knows when you read. This is obvious. It probably also knows where you read (even if that "where" is not stable, and is instead in a state of motion). It certainly knows when my birthday is, and no doubt it can collaborate (to put it euphemistically and anthropomorphically; it's probably more like accumulate, monopolize) with Spotify, or StubHub, or Google Calendar, to work out that I traveled on my birthday to attend a concert by a band I listen to quite a lot. Does this equate to knowing in a meaningful sense what I did and why? I don't know that this question is answerable, because it feels like our criteria for "to know why" are goalposts regularly moved so as to remain on just the right side of the human-machine boundary.
What is important, I think, is that it doesn't really matter whether Amazon can be said to know "why" a certain thing occurs. One question is then whether a form of writing exists, or can exist, capable of resisting an enforced effacement of interiority — one that manages to evade the sheer matter-of-factness of data-harvesting, whether by being so senseless that any attempt to read it becomes essentially stochastic, or, perhaps more interestingly, by using Amazon's own trick against it. If it doesn't matter what, so to speak, you put into a book, nor what you get out of it, but only what this engagement (quantifiably) looks like, then what if said book were all about "looking like": all about surfaces, impenetrable ironies, tonal flatnesses? I don't know whether this argument holds for Rooney's novel specifically, but reading an arguably "representative" contemporary text on the Kindle app seemed at times to bring out a sense of futility, a deliberate exhausted shallowness, from the novel's tone and form. So much of the book seems to consist of pointless descriptions of spaces and places and clicks and fucks. I thought, reading, this was Rooney's cynical anticipation of inevitable televising: armchair cinematography. But what if this is really a novel about surface as all that matters? It's tempting to characterize much of Rooney's political pontificating as "superficial." What would deep expression look like?
***
The descriptive potentials of these kinds of data have already been explored more extensively and at far greater scale. One chapter in Four Shades of Gray, Simon Rowberry's recent monograph about the Kindle, explores the potentials for treating the Kindle's well-known Popular Highlights function as a means of generating data on reading. Popular Highlights breaks down a given text into a list of quotations that have been most frequently highlighted by its readers. As Simon Rowberry notes, Popular Highlights was, between 2009 and 2017, a freestanding website.6
With Popular Highlights, the individual highlight function is contextualized for any user of the Kindle app as part of a broader data-gathering exercise. But the e-reader app form has made all physical features of the book customizable. Font and text size, page color, screen brightness, page orientation, pagination, line height, justification, and more can all be modified. On the Kindle app, users can generate these modifications on a setting-by-setting basis, or by way of a preset "theme" accessed from a submenu. Amazon gathers data every time a user explores this functionality, but short of making a data request, Popular Highlights is the only function revealed to the user as a data-generating feature rather than merely interactive.
In Rowberry's work, Popular Highlights provides scope for analysis in mapping the volume and distribution of reader highlights across the span of individual books. This analysis demonstrates how Popular Highlights data can reflect both a more normative model of reading, where a reader's focus clusters around important plot points while also exemplifying a distinctive digitally-mediated form of what Rowberry calls "social reading." In Rowberry's discussion of the latter, Popular Highlights in the Harry Potter series show, for example, ways that readers use the Kindle highlight function to "signal their fandom of specific characters while also sharing wisdom to a wider community."7
In the case of Rooney's novel, reading the text in terms of its most "popular," so to speak, moments yields some interpretively challenging results. The novel's most highlighted passage — with 1854 highlighters at the time of writing and 2110 at the final edit — states that "[w]e hate people for making mistakes so much more than we love them for doing good that the easiest way to live is to do nothing, say nothing, and love no one."8 The message here is somewhat at odds with a narrative that ultimately resolves itself with traditional bourgeois domestic contentment. Earlier in the novel, in a section highlighted by no less than 1074 different readers at the time of writing and 1222 at the time of editing, Rooney suggests that "[e]ach day, even each hour of each day, replaces and makes irrelevant the time before, and the events of our lives make sense only in relation to a perpetually updating timeline of news content."9 In a sense, we might suggest that this summary of the "discontinuous" present resonates with the assumptions underlying the value of Popular Highlights. In presenting a list of what, stripped of context, become essentially aphoristic comments on modernity, we might suggest that the products of Amazon's data-collection offer us a version of the text in a more consumable form still than the narrative. As the popularity of synopsis providers such as Blinkist grows, we might ask how far the Kindle app's shared annotations are an attempt to extend the same principle to the act of reading and deriving portable meaning from a literary text. In one way, this is not a new literary phenomenon: from allusion, to the commonplace book, to the political speech, texts have long been distilled or dismembered, circulating in reduced form. But the idea of a text only gaining its meaning, or even its readers, through a perpetually updating timeline of Popular Highlights recasts the reader as the data subject, always caught up in a feedback loop that is distinctly linked to digital reading.
The Kindle Toolbar provided an opportunity for comparable kinds of analysis of the data gathered on/by our group (see Figure 3), implying a shadow set of analogues to Popular Highlights. Every "interaction" with the toolbar was registered as a "tap" and included actions such as opening or closing the book, entering or exiting full page view, backgrounding the app, adding or removing bookmarks, opening Popular Highlights, opening the notebook, opening the "about this book" menu, opening the table of contents, and so on. For each of these, the Kindle app also recorded a timestamp, whether the screen was in portrait or landscape, whether the screen was "In Multi Window Mode," if "page flip" was available, and a whole host of other details. A single tap on our screens yields thirteen distinct data points in total. Figure 3 shows the number of "taps" recorded for each participant, running the gamut from the five toolbar interactions of Participant 4 (from whom Amazon did not harvest much data), to the 706 logged for Participant 6. As shown in Figure 4, which breaks down the same graph, the bulk of these interactions for all participants were opening the book or backgrounding the app, which provided insights about attention spans.
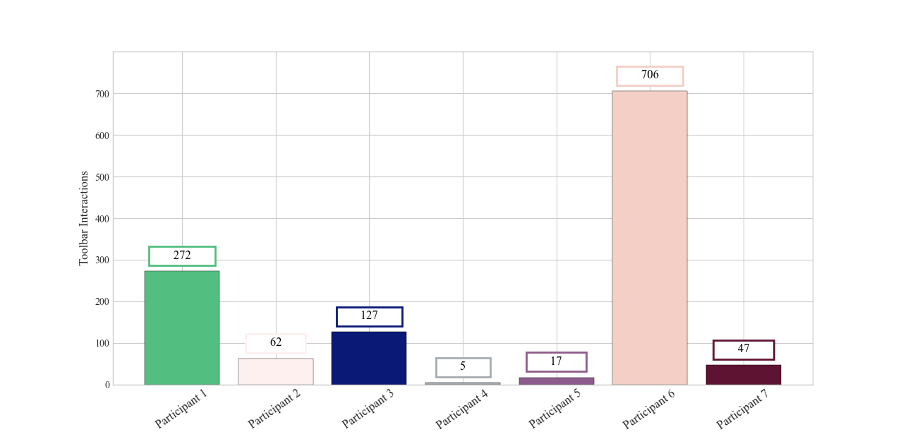
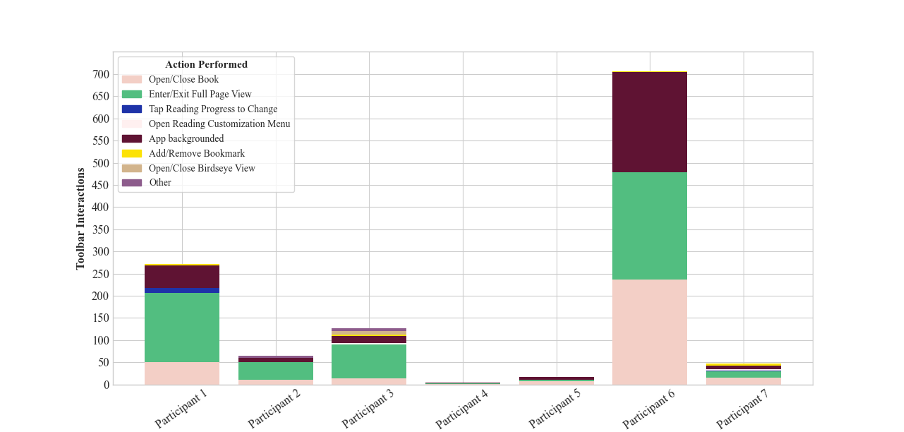
Figures 3 and 4 also open up an avenue for analysis that is critical rather than descriptive. Viewed one way, these figures visualize what Zuboff calls "behavioral surplus." In the early days of Google, she explains that the "continuous flow of collateral behavioral data" produced by users was used to improve those users' experience of the search engine: "Users provided the raw material in the form of behavioral data, and those data were harvested to improve speed, accuracy, and relevance."10 Unlike Figures 1 and 2, Figure 3 tells us more about Amazon's data-gathering activities than about readers or reading; Figure 4 might tell us something about reading but often only within the circumscribed parameters of the Kindle app — functions like customization, the bookmark, the birds-eye view are only truly meaningful when considered in relation to the holistic reading experience set out by the app. At best, we can rationalize these data on Zuboff's terms as a likely part of Amazon's product design process, part of the material fed back into improving the functioning of Amazon's products (improvements that will benefit both users and Amazon as the producer, although the needs of each might not always be aligned).
Maintaining the Data Subject
I was curious about how Amazon would, hypothetically, use deficient datasets like mine. The app wasn't able to record my start times, but it did record timestamps for every highlight I made while I read. How much could they infer from that data? Besides that, my highlighting habits and reading speed wildly varied between different reading sessions. I thought, naively, that Amazon would be hard-pressed to convert my data into formulas with any real predictive capabilities. If I read while eating or doing my makeup, my interactions with the app were limited to page turns achieved with an elbow to the arrow key. I often flipped back and forth, adding highlights retroactively. When I used my phone to read, it was usually while walking around Oxford. There were instances where I'd accidentally turned pages using my sleeve to wipe specks of rain from the screen, or left my unlocked phone in my pocket where it was jostled into turning pages and pressing toolbar buttons. All readers using the Kindle app have interacted with the platform in ways that disrupt accurate data harvesting from time to time: not every "tap" of the screen is an intentional behavior, and won't always be straightforwardly indicative of these readerly intentions. Algorithms already account for these anomalies, of course, and they are hardly enough to pose anything approaching a real challenge to rendition. But it feels like another kind of glitch in the system.
There are a series of assumptions about intention that must be made in order for Amazon to render our interactions with the screen as usable data. For example, a screen tap in the right location indicates a reader's desire to turn the page. I wondered if we could come up with more sustained methodologies for rearticulating these "rules of engagement" between reader and app? Perhaps one version of this is a book that dictates to the reader exactly when, where, and how they're read, a format where conformity becomes defiance. Perhaps there's a connection to be made with Simon's mass service in Rooney's novel, where his absolute sincerity and adherence to religious ritual fascinates the otherwise atheist Eileen. Ultimately, the belief itself isn't necessarily relevant to Eileen (he could even be worshiping a turtle, she thinks), but it is about the liberty Simon seems to find by eschewing individual self and participating in group behavior as a nondescript member of a congregation. There's a connection to be made here with the strange disappointment I'd felt when so much of the data in my .csv files was "NOT AVAILABLE." The feeling came from a place of self-absorption. I had been deprived of the same kind of curious pleasure toddlers get from seeing themselves in mirrors and adults get from taking the Myers-Briggs test. In my mind, this has serious implications for political discourse on data privacy. It betrays our tendency to imagine the issues of data harvesting and privacy in very individualistic terms, which is fatally counterproductive to our ability to address this as a systemic issue. After all, "private" is defined as the inverse of "public" and therefore data privacy as a concept is imagined in a way that resists a scaling outward as a social issue beyond ourselves. Why should I care if Amazon knows I took five hours to read a Sally Rooney novel?
* * *
Zuboff's story about Google continues with a necessary and transformative qualifier to the idea that data rendition is merely a feature of product design: under mounting pressure from investors, this "behavioral value reinvestment cycle was subjugated to the service of a new commercial calculation," and hence behavioral surplus was born as "the game-changing, zero-cost asset that was diverted from service improvement toward a genuine and highly lucrative market exchange."11 To be a data subject, then, is to have your interactions enumerated and monetized by default. In relation to the Kindle, Striphas argues that the behavioral surplus value created there forges a "new — abstract — type of reading whose value resides almost exclusively in its economic instrumentality." What follows for Striphas is the question of how such data might be classified or understood. Ultimately, Striphas accords with Zuboff's designation of user data as an "asset," while stressing its complex entanglement with its mode of production: users are "technologically obliged to work but without any pretense of labor as a socioeconomic ritual," rendering their data as "more like assets or fixed capital," even "human resources, albeit in the grossest sense of the term."12
Viewed this way, we might turn back to Figure 2 with a more critical approach in hand. Whereas a descriptive approach views Figure 2 as a comparative map of reading behaviors across a small sample, a critical approach can situate these data within a wider potential dataset that has been gathered by Amazon's sophisticated "ambient computing" infrastructure. The ideal Amazon consumer would close their Kindle app only to open Prime on another device to watch a movie; all the while, as they do so, their Roomba vacuum (a product created by iRobot, a company that at the time of writing is subject to acquisition by Amazon) would be cleaning their apartment, logging any changes to the layout of the rooms as it goes. The consumer might then order a takeout through Alexa on their Echo device; or, leaving their apartment, their exit would be registered on their Ring doorbell (another Amazon product); scrolling their phone as they walk down the street, the consumer might never leave sites supported by the cloud computing capabilities of Amazon Web Services; other Ring devices, too, would register that walk down the street, as might law enforcement agents using Rekognition, Amazon's facial recognition software. In this view, our Kindle data can only be understood as one small node in the networked system of total proprietary surveillance run by Amazon, the dystopian end result of Jeff Bezos's founding vision of "the everything store."
Emily West argues that at the center of Amazon's surveillance system is an attempt to shift "consumer subjectivity" from the normative neoliberal model of the "choosing subject" to a new "served self," whose "needs and preferences are learned over time and then catered to."13 West's conclusions about Alexa's place in this system are particularly pertinent for our purposes here:
Through the medium of voice, designed to be reassuring, familiar, and ever present (if incorporated into enough devices), Amazon encourages consumers to build intimacy with the persona of the brand through repeated interaction over time. Creating intimacy and trust with consumers is an affective tool that Amazon uses to normalize the surveillance that creates such valuable data commodities. Through Alexa, Amazon seeks to overcome resignation toward invasive data collection by transforming the experience of surveillance from one of control into something that feels like care.14
The trajectory tracked by West helps us further understand the status of the data subject. West's analysis acknowledges that, in our present digitally-mediated world, the served subject is by default resigned — sometimes emotionally, always functionally — to becoming a data subject. Whereas liberal critiques of data collection imagine the subject as a locus of rights and dignities that are impinged upon by data-gathering bodies, West's account of the served self suggests that, for companies like Amazon (and for their customers), these hallmarks of liberal subjecthood have already been relinquished, if indeed they were ever there to begin with. The challenge for Amazon is not, as liberal privacy campaigners would like to maintain, to encourage that relinquishment, but instead to assure that it is maintained by way of positive affect — by way of the nourishment and stability of intimacy, trust, and care, rather than by brittle feelings of sufferance and defeatedness.
The Kindle app returns data that promise a snapshot of reading practices, a snapshot that looks in a way like the fantasy of the reader-response theory of thirty to forty years ago. While it appears on the surface as if, with these data in hand, we can map the speed, the intensity, and the gradients of a reading subject, the patterns of habit or the event that reading can represent in an individual's experience, more fundamentally, the data we are permitted by law to request back from companies like Amazon provide no fully recuperable insights into the behaviors those data record. What we are left with is the figure of the data subject. In attempting to keep up with the rapid restructuring of private, social, and political life that has taken place under the sign of a now dominant platform capitalism, the data subject is the result of a compromise between big tech and liberal legal policy. The fantasy of transparent access to everyday behaviors and activities emerges from this compromise, as if the capture of data were just a happily contingent fact of an encompassing set of technologies and digital processes. But ultimately, what we look at when we view our reclaimed data — either individually, or scaled-up in an experimental manner as our project sought to do — are the traces of a subject who is by definition produced by the system in which they are engaged.
In Race After Technology, Ruha Benjamin explores "the New Jim Code," which constitutes the "employment of new technologies that reflect and reproduce existing inequities but that are promoted and perceived as more objective or progressive than the discriminatory systems of a previous era."15 Ideas such as algorithmic bias have in recent years become increasingly mainstream, and form an important part of online discourse about tech — often without much sign of better or alternative systems being generated. But Benjamin's deeper point concerns the second part of the formulation quoted above: the misprisions of conflating technological progress with social progress. For Benjamin, this conflation manifests as a "desire for objectivity, efficiency, profitability, and progress" that "fuels the pursuit of technical fixes across many different social arenas," many of which provide one more "road to inequity."16 The emergence of the data subject is one such flawed technical fix, a new manifestation of the fallacy that everyone stands equal before the law. If, in many jurisdictions, all data subjects possess equal recourse to requesting the data that is gathered on them by the platforms they use, this does not necessitate equality of treatment or use of that data. The differing data returns evidenced by our small reading group represent one frustratingly opaque appearance of this fact.
Yet there was still a utopian desire — as noted by some members of our collective — to work within the walls of this fractured system, using it to access a sense of transhistorical individuality. This conception of individuality is there in Zuboff's notion of "behavioral surplus": to have such a surplus, there must initially be some kind of straightforward datafied access to everyday behaviors and activities before their actual cultivation by self-reflective data regimes. This desire for a sense of individuality in the space of the platform appeared, for example, as the momentary but potent excitement felt by some members when choosing various settings in the Kindle app. To select a gray or beige or white background? To maximize the margins and limit your range of vision? To use a font so large it fills the entire screen or so small it hurts your eyes? The need to assess and compare between participants: who utilized which settings and where, when, and why? What might these selections reveal about the subject who makes them?
In a sense, abstract "individuality" — as it has been substantiated by the bourgeois novel — is a red herring here. It can even, when mobilized in the historically fraught form of biometrics, as Browne reminds us, be brutally corporeal: a "technology of measuring the living body" that enables it "to function as evidence" of regimented presence and personhood.17 Amazon's play at the purported codification of individuality exhibits the very fantasy that data gathering and aggregating apps like Kindle perpetuate, whether explicitly or implicitly. In airing the need for neat aesthetic choices like the hue of a background, the size of a font, the width and breadth and depth of its letters, what is actually communicated about the idea of the subject in the first place? Is it possible to write about Amazon and the data subject, with the inevitable autonomy one must cultivate in order to write at all, without replicating the very logic of value that we seek, in some sense, to critique? What mode of writing would be best suited to doing so? Or, otherwise: is the emphasis on "writing back" a red herring, too?
Throughout this essay, our interspersed autoethnographic reflections have represented an attempt to capture — and indeed "capture" seems too ill-chosen a word — what a collective writing practice could look like not under the false guise of complete anonymity (all differentiating metrics relinquished) but following a commitment to personal reflection and the expression made tangible by digital interaction. In doing so, we bump up against the risk of any semblance of subjective articulation being repurposed as sheer data, or what Jasbir Puar has called the "capacity machine" that is any discourse, really, post-cybernetic turn.18 The musings in this document are, to some extent, indicative of a capacity — ours — to produce, to reflect, to cultivate and delineate space for contemplation, within the relatively insulated arms of an elite university, no less. Still, these subjective enunciations sustain us. It would be detrimental, and not to mention futile, to argue otherwise.
If we are still unsure if there are any forms of writing capable of responding to data regimes in which harvesting practices are both quotidian and ubiquitous, we might focus instead on the basics: registering, as best we can, the materiality of existing with (and being structured by) digital capacities and the infrastructures that enable this interaction. The simple fact of multiple collaborators typing at once in a shared document — a real-time proximity that undoubtedly defines the digital age as such — is one attempt to keep a chronicle of our encounters. We conclude, then, with a final set of vignettes that further interpolate and trace the intimacies of engaging collaboratively with text in the digital age. (As I am writing these sentences in our shared Google document, I am conscious of my thumbs, typing furiously into the keyboard on my iPhone X. Flying across the glass, pausing, flinching, tapping, tapping. Always tapping. My friend, driving beside me, looks over my shoulder and remarks on the irony of this act: that I am contributing to this article in such a haphazard way, on an iPhone in a privatized vehicle speeding down the interstate, fielding emails and tweets and reels, with capacities now in hand that were once unthinkable. He looks at me. "So, you're writing about data harvesting on a smartphone?" He appears skeptical. I shrug. "Yeah.")
We bump up, inevitably, against one another; we sometimes diverge. These points of digital friction occur as a result of contact and provide brief respites, moments of reflection. We allow ourselves this luxury. We bump up against one another. In the reflections interspersed previously and soon to follow, there is less novelty than the data kings might like you to think. In the age of Amazon, we are still reflecting on — animating and inhabiting — flat surfaces with letters, numbers, and characters, alone or together, partaking in acts that advertise our capacities to engage: that create and sustain them. Not a luxury at all but a necessity not always guaranteed.
* * *
YOOO I ahte I. *I hate this. Terrible right? Im listening to you laugh on a voice message rn. Haha.laughing irl. Should we leave this here? Cowriting? Yeah let's leave this here. This feels very 'uchicago'. HAHAAH yooo this is major dramalolololol I am laughing and a half and a fricking half - also I will write about this now LMAOOahahahahahh so sally rooney lmao for realz - will have to check the edit history to even see who wrote this t hee. Hehe that's really beautiful[world]little scavengers no I should leave the typo
And this is only okay under the cover of anonymity
* * *
I'm reminded of Thomas Nagel's observation that many absurdists and nihilists make a fatally hypocritical move when they assume, in practice if not always in theory, that the fact of nothing mattering is a fact that matters. To be really consistent, this would have to not matter as well. Is it possible, then, that what a juxtaposition of Rooneyean ironics with Bezosian data-grinding really suggests is that "literary reading" is not a glitch, nor worryingly compatible, in a culture-industry sort of way, with platform capitalism, but rather that literary reading is just irrelevant, that it ceases to exist meaningfully; that attending to it, as we all in some sense do in our lives and careers, is barking up the wrong imaginary tree?
Maybe reading, now, is just not an interior act. The notion of reading as silent and private is in the grand scheme comparatively new. (The same might be true of prayer.) Perhaps at a time when we are reverting in so many ways to earlier modalities — feudal inequity, clutching authoritarianism — we're also going back to reading as a public and social act exclusively. The experience of reading is not expressed in Kindle highlights: there is no move from inner to outer. The experience of reading, now, is the Kindle highlight, and it is yours and everyone's and Amazon's.
* * *
I have never read a book in complete isolation. I have never read without the possibility of a reading public, without the opportunity to declare my opinion of a text to others. I know what books I'd take to a desert island, in other words, but I'm not quite sure I know what the indefinite impossibility of sharing my reaction to these texts would do to my reading practice.
I'm entertaining the idea of absolute privacy here, given it's something one comes to fetishize when reading on a Kindle. Yet before any discussion of how the Kindle app alters — or "destroys" — our traditional reading practices and publics, I figure it is useful to offer a defense of long-time reading publics. I am wary of overvaluing privacy, simply as a means of rejecting surveillance capitalism, because I believe we seek recognition and community through reading practices. In response to Ted Striphas's prescient, decade-old question, "How are we to safeguard the many freedoms — social, psychological, intellectual, political — with which reading has long and productively been associated?" I hope we don't answer "privacy!" but instead defend, locate, and adopt new reading publics.19
We would be naïve to ignore that we have always encountered "public" interventions in reading practice, even if less drastic. We would also be naïve to ignore the sociopolitical consequences of a reading practice substantiated by Amazon. In plainer terms, and in an American legal context, the highlighted passages or annotations in a Kindle reader contain information that would typically be, as Striphas notes, "subject to Fourth Amendment protections against unreasonable searches and seizures." Yet "because these data are transmitted electronically to the company and then archived in its computer cloud, US federal law considers them to be not pieces of private information but instead 'stored communications.'"20 We are right to harbor fears around these "stored communications."
The late Lauren Berlant asked us to "brainstorm [our] own examples of structural and affective alienation" toward the end of their introduction to On the Inconvenience of Other People (2022).21 Berlant's prompt gets its own paragraph in the middle of two bolded section breaks: you're meant to really do it. At this moment, I am seated in a laptop-free room but am typing on my phone because textual interfaces are portable. I am grateful for this infrastructure. It defines my writing practice. I would be dishonest to declare that the Kindle app interface is a form of structural and affective alienation. I don't feel alienated. Berlant also writes that the writer, artist, theorist — or maybe just plain reader — has an obligation to "proffer transitional infrastructures for the extended meanwhile."22Kindle app reading reminds us that we read in community and that we have a claim to our community. I also hope it generates an obligation to protect the infrastructures that enable those communities. That may mean protection of precarious academic staff or the ability to teach underdiscussed material. I don't know how bad it could get in the extended meanwhile, but I do know that we are still here as a collective co-reading and co-writing. The answer to surveillance capitalism is not to retreat from our materials but to remain explicit in our commitments to each other. It is to pick up practices of détournement, as Striphas suggests, where readers screw with the data through nonsensical notes and irony.23 The best type of détournement might just be plain old readerly community: moments when we come together and mock a highlighted passage, only to ultimately join in.
Détournement may also arrive in the form of shadow libraries. Z-Library, the now defunct e-library of approximately twelve million books, is celebrated for its ability to provide accessible texts to readers in emerging economies or students at universities who perhaps cannot afford another academic monograph. I wish I had been more earnest when I tweeted, "wedding registry of dif levels of donations to z-library," given Z-Library's status as a non-profit reliant on donations.
Z-Library is most obviously a form of détournement in its rejection of the literary marketplace, but I can't help but also note the Portable Document Format (PDF) as a refreshing kind of textual interface. Unlike in the case of the Kindle app, with its highlights function and curated recommendations for reading practice, I always feel a bit roguish while reading PDFs downloaded from Z-Library. It's hard for me to separate reading Paul B. Preciado's Testo Junkie and his critique of medical and legal institutions, for instance, from the practice of détournement I exercised in obtaining the text from a shadow library.
Most of the time, it feels like the folder on my desktop "e-library" — created on Tuesday, November 17, 2020 at 09:04 and last modified on Monday, December 12, 2022 at 11:08 — is fit to survive the past and future. But when my laptop broke down in February 2022, I found myself running through a kind of digital house-on-fire in preservation of my textual interfaces. Seated in an IT office, with the opportunity to send a few files to myself in the last moments of my laptop's life, I dragged my most beloved marked-up Z-Library files to my Google Drive.
The documents in my "e-library" possess character. They often were downloaded out of a sense of urgency, even if I ultimately purchased the physical text or checked it out from a traditional lending library. These PDFs can also be unbound or broken: one can misorder the pages on the Sidebar.
I circulate these texts to my friends. I can give them my marked-up copies — featuring blue and pink "highlights," which I've easily copy-and-pasted to other documents, or my "stickies" in the margins — or duplicate them anew. I look at my "e-library" and know its contents belong to me more than, or certainly as much as, any texts I've ever owned.
The Privacy Settings Collective was formed from members of an experimental reading group that met at the University of Oxford in June 2022. Funding to support the reading group, and the data processing that resulted, was provided by the Minderoo Foundation's AI Governance Fund, administered through The Oxford Centre Research Centre in the Humanities (TORCH). Members — James T. Bowen (@J_T_Bowen), Isobelle Cherry, Katherine Franco (@kathgr8), Adam Guy (@_Adam_Guy), Lillian Hingley (@HingleyTheory), Ben Philipps (@BenAPhilipps), Maya Sibul (@mls2288) — wrote this article on a Google Doc, meeting on Google Meet, MS Teams, and Zoom from various locations in the UK and the US.
References
- Shoshana Zuboff, The Age of Surveillance Capitalism: The Fight for the Future at the New Frontier of Power (London: Profile, 2019), 112. [⤒]
- Alison Flood, "Sally Rooney's Beautiful World, Where Are You Tops UK Book Charts,", the Guardian (14 September 2021), unpaginated. <https://www.theguardian.com/books/2021/sep/14/sally-rooneys-beautiful-world-where-are-you-tops-uk-book-charts> [⤒]
- Ted Striphas, "The Abuses of Literacy," Communication and Critical/Cultural Studies 7 no.3 (2010): 308. For other discussions of the Kindle, see: Mark McGurl, Everything and Less: The Novel in the Age of Amazon (London: Verso, 2021); Leah Price, What We Talk About When We Talk About Books: The History and Future of Reading (New York: Basic Books, 2019); Simon Peter Rowberry, Four Shades of Gray: The Amazon Kindle Platform (Cambridge, MA: MIT Press, 2022); Whitney Trettien, "Tracked" in Further Reading, ed. by Matthew Rubery and Leah Price (Oxford: Oxford University Press, 2020), 311-24. [⤒]
- Simone Browne, Dark Matters: On the Surveillance of Blackness (Durham, NC: Duke University, 2015), 109. [⤒]
- See "Art. 15 GDPR: Right of Access by the Data Subject," General Data Protection Regulation (GDPR), <https://gdpr.eu/article-15-right-of-access/> ; "Right of Access by the Data Subject," Data Protection Act 2018, <https://www.legislation.gov.uk/ukpga/2018/12/part/3/chapter/3/crossheading/data-subjects-right-of-access/enacted> [⤒]
- Rowberry, 121. [⤒]
- Rowberry, 135. For another example, see Patterns of Popularity: Towards a Holistic Understanding of Contemporary Bestselling Fiction <https://www.littvet.uu.se/research/current-research/patterns-of-popularity/>. Established by Karl Berglund and Mats Dahlöf, this project uses a partnership with the audiobook-streaming platform Storytel to map reading practices across a total of c.74.6 million data points, distributed across c.432,000 individual readers. [⤒]
- Sally Rooney, Beautiful World, Where Are You (London: Faber, 2021), 186. Popular Highlight numbers quoted in this article were recorded on 1 March and 26 November 2023; across the time of writing these numbers fluctuated, though their relative popularity remained stable. [⤒]
- Rooney, 38. [⤒]
- Zuboff, 68-9. [⤒]
- Zuboff, 81. [⤒]
- Striphas, 306. [⤒]
- Emily West, Buy Now: How Amazon Branded Convenience and Normalized Monopoly (Cambridge, MA: MIT Press, 2022), 134. [⤒]
- West, 136-7. [⤒]
- Ruha Benjamin, Race After Technology: Abolitionist Tools for the New Jim Code (Cambridge: Polity, 2019), 10. [⤒]
- Benjamin, 11. [⤒]
- Browne, 109. [⤒]
- Jasbir K. Puar, The Right to Maim: Debility, Capacity, Disability (Durham, NC: Duke University Press, 2017), 13. [⤒]
- Striphas, 310. [⤒]
- Striphas, 308. [⤒]
- Lauren Berlant, On the Inconvenience of Other People (Durham, NC: Duke University Press, 2022), 26. [⤒]
- Berlant, 19. [⤒]
- Striphas, 310. [⤒]
Related reading
 Young Adult Readers and the Genres of Online Book Reviewing
Third Person Random
Breakfast with AlgoBooks: Meet the Future of Reader Recommendation
Reading through Wattpad’s Classification and Discoverability Algorithms
SEO and the essay: what does it tell us about “AI”-generated text and literary culture?
BookTok and the Rituals of Recommendation
Reading Like Rory: Post-Digital Reading on BookTok
Introduction: Reading with Algorithms
Young Adult Readers and the Genres of Online Book Reviewing
Third Person Random
Breakfast with AlgoBooks: Meet the Future of Reader Recommendation
Reading through Wattpad’s Classification and Discoverability Algorithms
SEO and the essay: what does it tell us about “AI”-generated text and literary culture?
BookTok and the Rituals of Recommendation
Reading Like Rory: Post-Digital Reading on BookTok
Introduction: Reading with Algorithms